Last week we looked at linear models with 1 predictor (either
continuous or categorical with 2 levels). Now we are going to extend
this to linear models with more than 1 predictor.
We have already seen the assumptions of multiple linear regression
last week. They are essentially the same as for simple linear regression
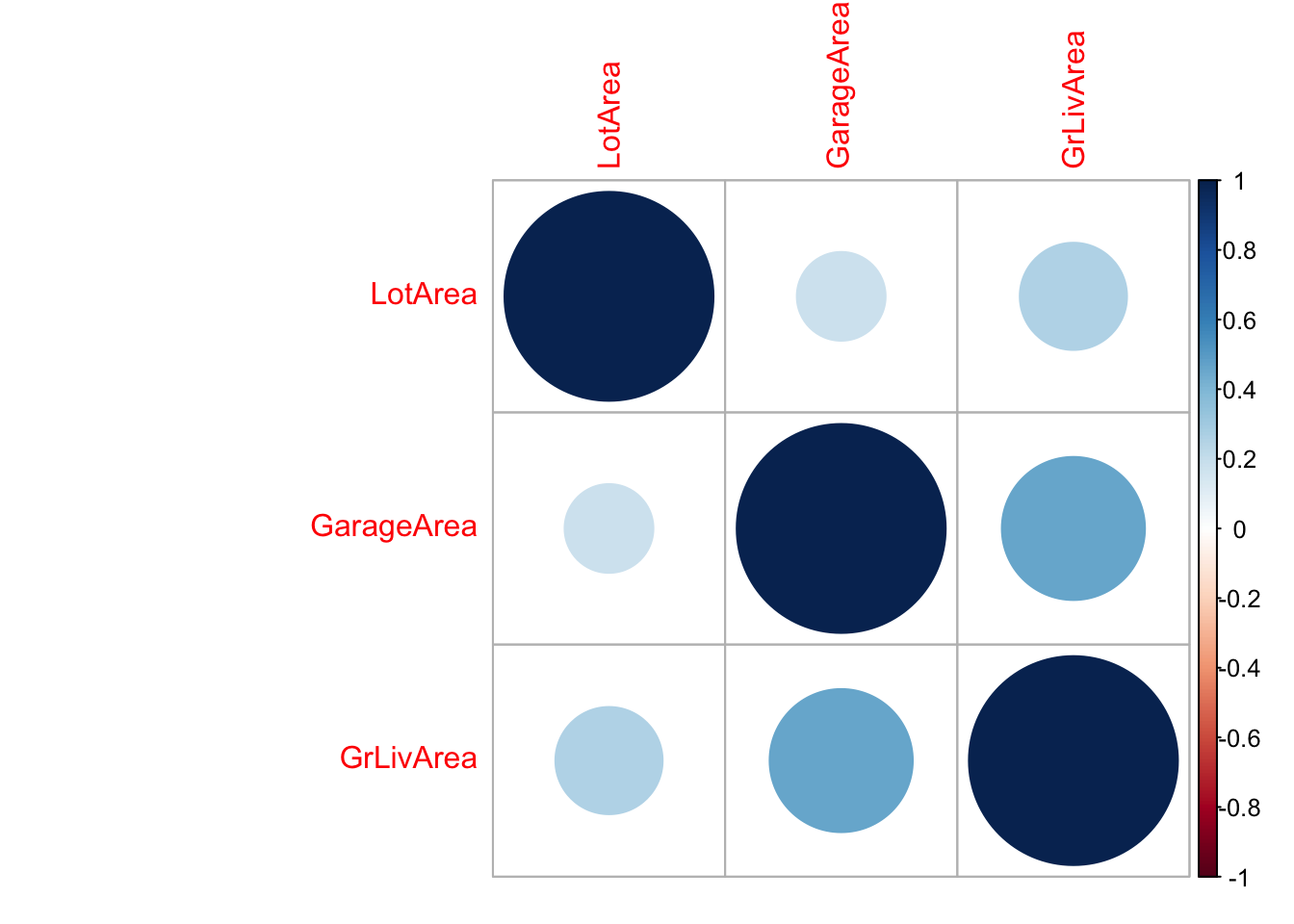
but now we should also check that the predictors are not correlated.
Open RStudio.
Model fitting
Model fit can be achieved as in simple linear regression using
lm().
the only thing to take into account is how to change the formula
argument:
outcome ~ predictor1 + predictor2: tests main effects
only of these two predictorsoutcome ~ predictor1 * predictor2: tests all main
effects and the interaction effect of these two predictorsoutcome ~ predictor1 * predictor2 * predictor3: tests
all main effects and all interaction effect of these three
predictorsoutcome ~ predictor1 + predictor2 + predictor3 + predictor1*predictor2:
tests main all three main effects and only the interaction effect of the
first and second predictor
Download the house_prices.csv dataset from the Github
folder and load it in R:
library(tidyverse)
house_prices = read_csv('data/house_prices.csv')
##
## ── Column specification ─────────────────────────────────────────────────────────────────────────────────────────────
## cols(
## .default = col_character(),
## Id = col_double(),
## MSSubClass = col_double(),
## LotFrontage = col_double(),
## LotArea = col_double(),
## OverallQual = col_double(),
## OverallCond = col_double(),
## YearBuilt = col_double(),
## YearRemodAdd = col_double(),
## MasVnrArea = col_double(),
## BsmtFinSF1 = col_double(),
## BsmtFinSF2 = col_double(),
## BsmtUnfSF = col_double(),
## TotalBsmtSF = col_double(),
## `1stFlrSF` = col_double(),
## `2ndFlrSF` = col_double(),
## LowQualFinSF = col_double(),
## GrLivArea = col_double(),
## BsmtFullBath = col_double(),
## BsmtHalfBath = col_double(),
## FullBath = col_double()
## # ... with 18 more columns
## )
## ℹ Use `spec()` for the full column specifications.
glimpse(house_prices)
## Rows: 1,460
## Columns: 81
## $ Id <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26…
## $ MSSubClass <dbl> 60, 20, 60, 70, 60, 50, 20, 60, 50, 190, 20, 60, 20, 20, 20, 45, 20, 90, 20, 20, 60, 45, 20, …
## $ MSZoning <chr> "RL", "RL", "RL", "RL", "RL", "RL", "RL", "RL", "RM", "RL", "RL", "RL", "RL", "RL", "RL", "RM…
## $ LotFrontage <dbl> 65, 80, 68, 60, 84, 85, 75, NA, 51, 50, 70, 85, NA, 91, NA, 51, NA, 72, 66, 70, 101, 57, 75, …
## $ LotArea <dbl> 8450, 9600, 11250, 9550, 14260, 14115, 10084, 10382, 6120, 7420, 11200, 11924, 12968, 10652, …
## $ Street <chr> "Pave", "Pave", "Pave", "Pave", "Pave", "Pave", "Pave", "Pave", "Pave", "Pave", "Pave", "Pave…
## $ Alley <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "Grvl", N…
## $ LotShape <chr> "Reg", "Reg", "IR1", "IR1", "IR1", "IR1", "Reg", "IR1", "Reg", "Reg", "Reg", "IR1", "IR2", "I…
## $ LandContour <chr> "Lvl", "Lvl", "Lvl", "Lvl", "Lvl", "Lvl", "Lvl", "Lvl", "Lvl", "Lvl", "Lvl", "Lvl", "Lvl", "L…
## $ Utilities <chr> "AllPub", "AllPub", "AllPub", "AllPub", "AllPub", "AllPub", "AllPub", "AllPub", "AllPub", "Al…
## $ LotConfig <chr> "Inside", "FR2", "Inside", "Corner", "FR2", "Inside", "Inside", "Corner", "Inside", "Corner",…
## $ LandSlope <chr> "Gtl", "Gtl", "Gtl", "Gtl", "Gtl", "Gtl", "Gtl", "Gtl", "Gtl", "Gtl", "Gtl", "Gtl", "Gtl", "G…
## $ Neighborhood <chr> "CollgCr", "Veenker", "CollgCr", "Crawfor", "NoRidge", "Mitchel", "Somerst", "NWAmes", "OldTo…
## $ Condition1 <chr> "Norm", "Feedr", "Norm", "Norm", "Norm", "Norm", "Norm", "PosN", "Artery", "Artery", "Norm", …
## $ Condition2 <chr> "Norm", "Norm", "Norm", "Norm", "Norm", "Norm", "Norm", "Norm", "Norm", "Artery", "Norm", "No…
## $ BldgType <chr> "1Fam", "1Fam", "1Fam", "1Fam", "1Fam", "1Fam", "1Fam", "1Fam", "1Fam", "2fmCon", "1Fam", "1F…
## $ HouseStyle <chr> "2Story", "1Story", "2Story", "2Story", "2Story", "1.5Fin", "1Story", "2Story", "1.5Fin", "1.…
## $ OverallQual <dbl> 7, 6, 7, 7, 8, 5, 8, 7, 7, 5, 5, 9, 5, 7, 6, 7, 6, 4, 5, 5, 8, 7, 8, 5, 5, 8, 5, 8, 5, 4, 4, …
## $ OverallCond <dbl> 5, 8, 5, 5, 5, 5, 5, 6, 5, 6, 5, 5, 6, 5, 5, 8, 7, 5, 5, 6, 5, 7, 5, 7, 8, 5, 7, 5, 6, 6, 4, …
## $ YearBuilt <dbl> 2003, 1976, 2001, 1915, 2000, 1993, 2004, 1973, 1931, 1939, 1965, 2005, 1962, 2006, 1960, 192…
## $ YearRemodAdd <dbl> 2003, 1976, 2002, 1970, 2000, 1995, 2005, 1973, 1950, 1950, 1965, 2006, 1962, 2007, 1960, 200…
## $ RoofStyle <chr> "Gable", "Gable", "Gable", "Gable", "Gable", "Gable", "Gable", "Gable", "Gable", "Gable", "Hi…
## $ RoofMatl <chr> "CompShg", "CompShg", "CompShg", "CompShg", "CompShg", "CompShg", "CompShg", "CompShg", "Comp…
## $ Exterior1st <chr> "VinylSd", "MetalSd", "VinylSd", "Wd Sdng", "VinylSd", "VinylSd", "VinylSd", "HdBoard", "BrkF…
## $ Exterior2nd <chr> "VinylSd", "MetalSd", "VinylSd", "Wd Shng", "VinylSd", "VinylSd", "VinylSd", "HdBoard", "Wd S…
## $ MasVnrType <chr> "BrkFace", "None", "BrkFace", "None", "BrkFace", "None", "Stone", "Stone", "None", "None", "N…
## $ MasVnrArea <dbl> 196, 0, 162, 0, 350, 0, 186, 240, 0, 0, 0, 286, 0, 306, 212, 0, 180, 0, 0, 0, 380, 0, 281, 0,…
## $ ExterQual <chr> "Gd", "TA", "Gd", "TA", "Gd", "TA", "Gd", "TA", "TA", "TA", "TA", "Ex", "TA", "Gd", "TA", "TA…
## $ ExterCond <chr> "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA…
## $ Foundation <chr> "PConc", "CBlock", "PConc", "BrkTil", "PConc", "Wood", "PConc", "CBlock", "BrkTil", "BrkTil",…
## $ BsmtQual <chr> "Gd", "Gd", "Gd", "TA", "Gd", "Gd", "Ex", "Gd", "TA", "TA", "TA", "Ex", "TA", "Gd", "TA", "TA…
## $ BsmtCond <chr> "TA", "TA", "TA", "Gd", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA…
## $ BsmtExposure <chr> "No", "Gd", "Mn", "No", "Av", "No", "Av", "Mn", "No", "No", "No", "No", "No", "Av", "No", "No…
## $ BsmtFinType1 <chr> "GLQ", "ALQ", "GLQ", "ALQ", "GLQ", "GLQ", "GLQ", "ALQ", "Unf", "GLQ", "Rec", "GLQ", "ALQ", "U…
## $ BsmtFinSF1 <dbl> 706, 978, 486, 216, 655, 732, 1369, 859, 0, 851, 906, 998, 737, 0, 733, 0, 578, 0, 646, 504, …
## $ BsmtFinType2 <chr> "Unf", "Unf", "Unf", "Unf", "Unf", "Unf", "Unf", "BLQ", "Unf", "Unf", "Unf", "Unf", "Unf", "U…
## $ BsmtFinSF2 <dbl> 0, 0, 0, 0, 0, 0, 0, 32, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 668, 0, 486, 0, 0, 0…
## $ BsmtUnfSF <dbl> 150, 284, 434, 540, 490, 64, 317, 216, 952, 140, 134, 177, 175, 1494, 520, 832, 426, 0, 468, …
## $ TotalBsmtSF <dbl> 856, 1262, 920, 756, 1145, 796, 1686, 1107, 952, 991, 1040, 1175, 912, 1494, 1253, 832, 1004,…
## $ Heating <chr> "GasA", "GasA", "GasA", "GasA", "GasA", "GasA", "GasA", "GasA", "GasA", "GasA", "GasA", "GasA…
## $ HeatingQC <chr> "Ex", "Ex", "Ex", "Gd", "Ex", "Ex", "Ex", "Ex", "Gd", "Ex", "Ex", "Ex", "TA", "Ex", "TA", "Ex…
## $ CentralAir <chr> "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y"…
## $ Electrical <chr> "SBrkr", "SBrkr", "SBrkr", "SBrkr", "SBrkr", "SBrkr", "SBrkr", "SBrkr", "FuseF", "SBrkr", "SB…
## $ `1stFlrSF` <dbl> 856, 1262, 920, 961, 1145, 796, 1694, 1107, 1022, 1077, 1040, 1182, 912, 1494, 1253, 854, 100…
## $ `2ndFlrSF` <dbl> 854, 0, 866, 756, 1053, 566, 0, 983, 752, 0, 0, 1142, 0, 0, 0, 0, 0, 0, 0, 0, 1218, 0, 0, 0, …
## $ LowQualFinSF <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
## $ GrLivArea <dbl> 1710, 1262, 1786, 1717, 2198, 1362, 1694, 2090, 1774, 1077, 1040, 2324, 912, 1494, 1253, 854,…
## $ BsmtFullBath <dbl> 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, …
## $ BsmtHalfBath <dbl> 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, …
## $ FullBath <dbl> 2, 2, 2, 1, 2, 1, 2, 2, 2, 1, 1, 3, 1, 2, 1, 1, 1, 2, 1, 1, 3, 1, 2, 1, 1, 2, 1, 2, 1, 1, 1, …
## $ HalfBath <dbl> 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
## $ BedroomAbvGr <dbl> 3, 3, 3, 3, 4, 1, 3, 3, 2, 2, 3, 4, 2, 3, 2, 2, 2, 2, 3, 3, 4, 3, 3, 3, 3, 3, 3, 3, 2, 1, 3, …
## $ KitchenAbvGr <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
## $ KitchenQual <chr> "Gd", "TA", "Gd", "Gd", "Gd", "TA", "Gd", "TA", "TA", "TA", "TA", "Ex", "TA", "Gd", "TA", "TA…
## $ TotRmsAbvGrd <dbl> 8, 6, 6, 7, 9, 5, 7, 7, 8, 5, 5, 11, 4, 7, 5, 5, 5, 6, 6, 6, 9, 6, 7, 6, 6, 7, 5, 7, 6, 4, 6,…
## $ Functional <chr> "Typ", "Typ", "Typ", "Typ", "Typ", "Typ", "Typ", "Typ", "Min1", "Typ", "Typ", "Typ", "Typ", "…
## $ Fireplaces <dbl> 0, 1, 1, 1, 1, 0, 1, 2, 2, 2, 0, 2, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 2, 0, 0, …
## $ FireplaceQu <chr> NA, "TA", "TA", "Gd", "TA", NA, "Gd", "TA", "TA", "TA", NA, "Gd", NA, "Gd", "Fa", NA, "TA", N…
## $ GarageType <chr> "Attchd", "Attchd", "Attchd", "Detchd", "Attchd", "Attchd", "Attchd", "Attchd", "Detchd", "At…
## $ GarageYrBlt <dbl> 2003, 1976, 2001, 1998, 2000, 1993, 2004, 1973, 1931, 1939, 1965, 2005, 1962, 2006, 1960, 199…
## $ GarageFinish <chr> "RFn", "RFn", "RFn", "Unf", "RFn", "Unf", "RFn", "RFn", "Unf", "RFn", "Unf", "Fin", "Unf", "R…
## $ GarageCars <dbl> 2, 2, 2, 3, 3, 2, 2, 2, 2, 1, 1, 3, 1, 3, 1, 2, 2, 2, 2, 1, 3, 1, 2, 2, 1, 3, 2, 3, 1, 1, 1, …
## $ GarageArea <dbl> 548, 460, 608, 642, 836, 480, 636, 484, 468, 205, 384, 736, 352, 840, 352, 576, 480, 516, 576…
## $ GarageQual <chr> "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "Fa", "Gd", "TA", "TA", "TA", "TA", "TA", "TA…
## $ GarageCond <chr> "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA…
## $ PavedDrive <chr> "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y"…
## $ WoodDeckSF <dbl> 0, 298, 0, 0, 192, 40, 255, 235, 90, 0, 0, 147, 140, 160, 0, 48, 0, 0, 0, 0, 240, 0, 171, 100…
## $ OpenPorchSF <dbl> 61, 0, 42, 35, 84, 30, 57, 204, 0, 4, 0, 21, 0, 33, 213, 112, 0, 0, 102, 0, 154, 0, 159, 110,…
## $ EnclosedPorch <dbl> 0, 0, 0, 272, 0, 0, 0, 228, 205, 0, 0, 0, 0, 0, 176, 0, 0, 0, 0, 0, 0, 205, 0, 0, 0, 0, 0, 0,…
## $ `3SsnPorch` <dbl> 0, 0, 0, 0, 0, 320, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ ScreenPorch <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 176, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ PoolArea <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
## $ PoolQC <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ Fence <chr> NA, NA, NA, NA, NA, "MnPrv", NA, NA, NA, NA, NA, NA, NA, NA, "GdWo", "GdPrv", NA, NA, NA, "Mn…
## $ MiscFeature <chr> NA, NA, NA, NA, NA, "Shed", NA, "Shed", NA, NA, NA, NA, NA, NA, NA, NA, "Shed", "Shed", NA, N…
## $ MiscVal <dbl> 0, 0, 0, 0, 0, 700, 0, 350, 0, 0, 0, 0, 0, 0, 0, 0, 700, 500, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ MoSold <dbl> 2, 5, 9, 2, 12, 10, 8, 11, 4, 1, 2, 7, 9, 8, 5, 7, 3, 10, 6, 5, 11, 6, 9, 6, 5, 7, 5, 5, 12, …
## $ YrSold <dbl> 2008, 2007, 2008, 2006, 2008, 2009, 2007, 2009, 2008, 2008, 2008, 2006, 2008, 2007, 2008, 200…
## $ SaleType <chr> "WD", "WD", "WD", "WD", "WD", "WD", "WD", "WD", "WD", "WD", "WD", "New", "WD", "New", "WD", "…
## $ SaleCondition <chr> "Normal", "Normal", "Normal", "Abnorml", "Normal", "Normal", "Normal", "Normal", "Abnorml", "…
## $ SalePrice <dbl> 208500, 181500, 223500, 140000, 250000, 143000, 307000, 200000, 129900, 118000, 129500, 34500…
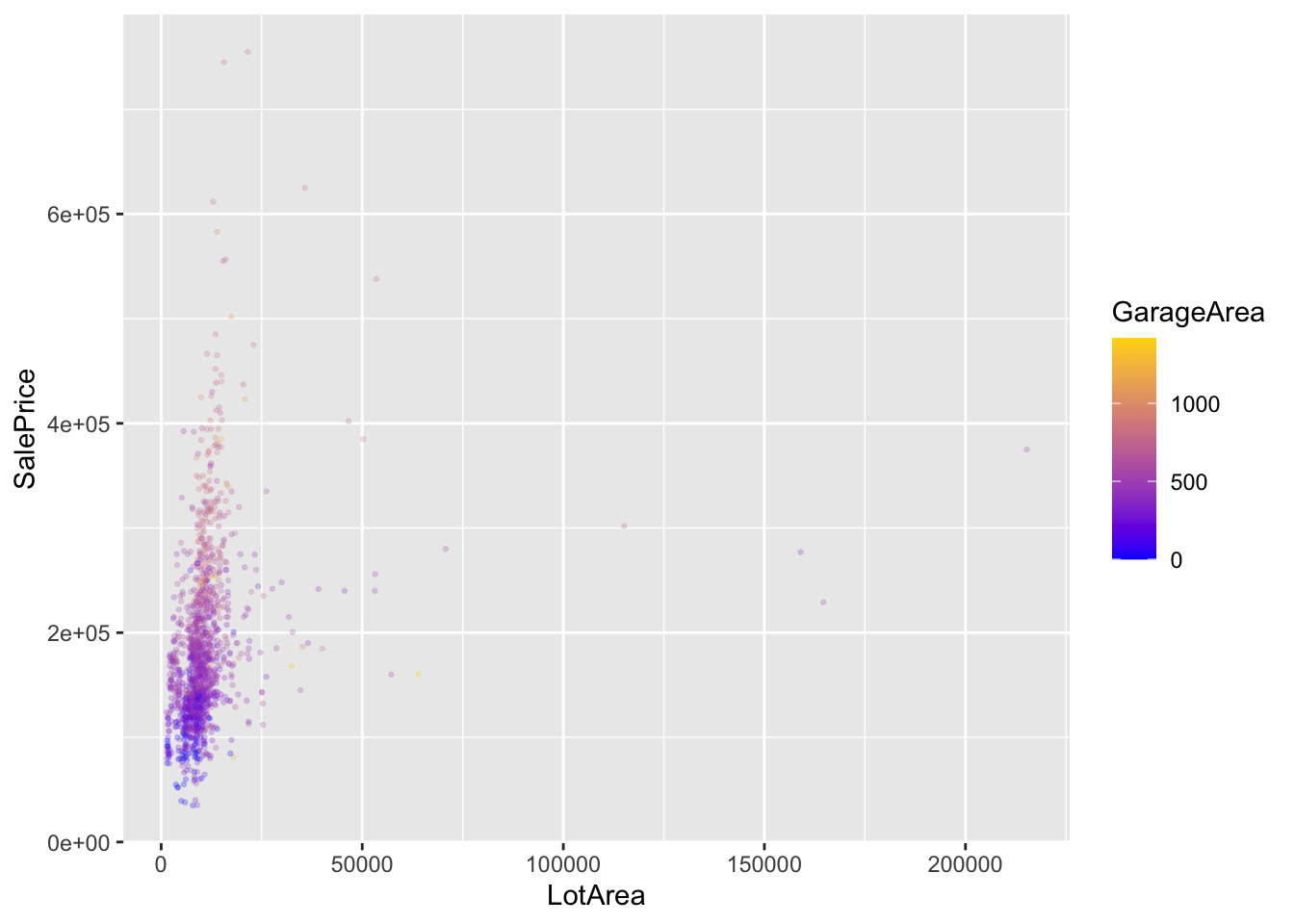
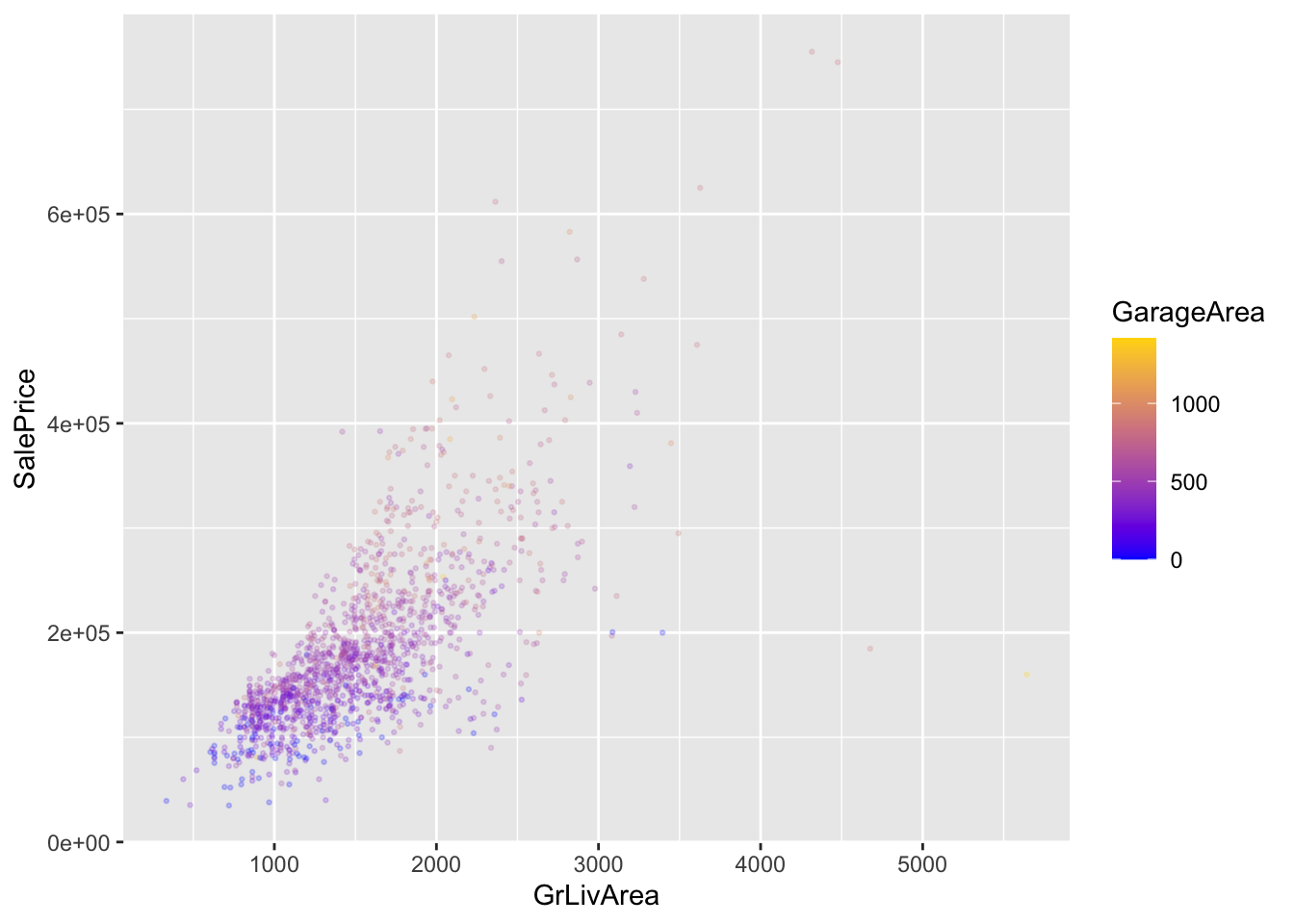
GrLivArea: Above grade (ground) living area square feet
LotArea: Lot size in square feet
GarageArea: Size of garage in square feet
Main effects model:
model_fit = lm(SalePrice ~ LotArea + GarageArea + GrLivArea,
data = house_prices)
summary(model_fit)
##
## Call:
## lm(formula = SalePrice ~ LotArea + GarageArea + GrLivArea, data = house_prices)
##
## Residuals:
## Min 1Q Median 3Q Max
## -500375 -22148 -977 19699 315357
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -8031.7724 4154.7983 -1.933 0.053414 .
## LotArea 0.4821 0.1346 3.582 0.000353 ***
## GarageArea 137.0127 6.8638 19.962 < 2e-16 ***
## GrLivArea 78.5759 2.8472 27.597 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 49400 on 1456 degrees of freedom
## Multiple R-squared: 0.6142, Adjusted R-squared: 0.6134
## F-statistic: 772.6 on 3 and 1456 DF, p-value: < 2.2e-16
Full model (including also interactions effects):
model_fit = lm(SalePrice ~ LotArea*GarageArea*GrLivArea,
data = house_prices)
summary(model_fit)
##
## Call:
## lm(formula = SalePrice ~ LotArea * GarageArea * GrLivArea, data = house_prices)
##
## Residuals:
## Min 1Q Median 3Q Max
## -289270 -20605 590 19121 288645
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 8.894e+04 1.229e+04 7.235 7.49e-13 ***
## LotArea -2.232e+00 1.166e+00 -1.915 0.05574 .
## GarageArea -9.108e+01 2.109e+01 -4.319 1.68e-05 ***
## GrLivArea 8.923e+00 7.726e+00 1.155 0.24831
## LotArea:GarageArea 6.629e-03 1.437e-03 4.614 4.30e-06 ***
## LotArea:GrLivArea 1.935e-03 5.433e-04 3.562 0.00038 ***
## GarageArea:GrLivArea 1.522e-01 1.208e-02 12.599 < 2e-16 ***
## LotArea:GarageArea:GrLivArea -4.305e-06 4.774e-07 -9.016 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 45950 on 1452 degrees of freedom
## Multiple R-squared: 0.667, Adjusted R-squared: 0.6654
## F-statistic: 415.5 on 7 and 1452 DF, p-value: < 2.2e-16
# Note: Have main effects changed?